From Zero to Full-Stack App on k3s with CI/CD: A Complete Walkthrough
I recently deployed a coffee review app (Next.js frontend, Supabase backend) entirely on a single...


I recently deployed a coffee review app (Next.js frontend, Supabase backend) entirely on a single...





In this tutorial, we’ll walk through the process of setting up a WordPress site on Ubuntu...
Google now allows you specify the size of your boot disk larger than 10GB when you create your instance. In any case, if you need to resize your boot disk for any reason, these are the steps I followed. Here I’ve attached...
Classes Classes are one of the building blocks of object-oriented programming. Think of them as blueprints for creating objects. When we just throw variables and methods inside a Ruby file, it’s very loosely associated....
Assume you’ve already verified your certificates and keys on the sever side (checksum should be the same): openssl x509 -noout -modulus -in mycert.pem openssl rsa -noout -modulus -in mykey.pem mysql> show variables like...

Agentic DevOps at Home: An Enterprise-Grade, Open-Source Blueprint for Solo Developers You can run...
Read More
Local LLMs 101: What Really Happens When You Run an AI Model on Your Own Machine You’re a...
Read More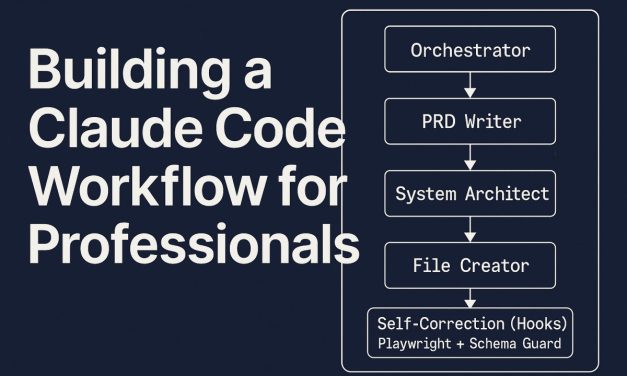
Learn how to architect, orchestrate, and optimize a world-class AI coding workflow with Claude...
Read More
How to optimize your Claude Code projects for maximum efficiency and minimal confusion Imagine...
Read More
Most developers treat AI coding assistants like faster autocomplete—asking for snippets here,...
Read More
What I’ve learned from building real-world AI automation systems that actually work The AI...
Read More
Vector databases are becoming essential components of modern AI-driven applications, enabling...
Read More
Running large language models (LLMs) like Qwen3-235B using ollama on a multi-GPU setup involves a...
Read More
Which Self-Hosted CMS Makes AI Integration Easiest? If you’re building modern content...
Read More
AI Agents are rapidly transforming how we interact with technology, capable of performing complex...
Read More
Blog Post HTML From Code to Live App in Your Homelab: Your Personal Cloud, No Bills Attached! Ever...
Read More
In today’s rapidly evolving tech landscape, the concept of “vibe coding” has...
Read More
Options Strategies for High VIX Environments (35+) In highly volatile markets—typically marked by...
Read More
Periods where the VIX (Volatility Index) remains elevated—especially above the 40 mark—tend to be...
Read More
In the rapidly evolving landscape of AI agents, selecting the right Large Language Model (LLM) has...
Read More
In today’s rapidly evolving technological landscape, artificial intelligence (AI) presents...
Read More
Recent Comments